2 Author’s name
MARC: 100a
Polish author’s name field: author_name.R
Harmonize individual data function: polish_author.R
Render author name field: author_name.qmd
Author’s name section’s summary tables offer insights into the dataset’s integrity, illustrating the accepted and discarded author names. An examination of missing values in the original dataset provides transparency regarding data completeness. The inclusion of information on name variants and pseudonyms enriches the analysis, addressing nuances in authorship representation. This comprehensive approach ensures a thorough understanding of the dataset’s composition and the intricacies associated with author identification.
2.1 Complete Dataset Overview
- Unique accepted entries in original data: 196891
- Unique discarded entries in original data (excluding NA cases): 29
- Original documents with non-NA titles 747538 / 1187813 (62.9%)
- Original documents with missing (NA) titles 440275 / 1187813 documents (37.1%)
2.1.2 Auxiliary files
2.2 Subset Analysis: 1809-1917
Unique discarded entries in original data (excluding NA cases): 19
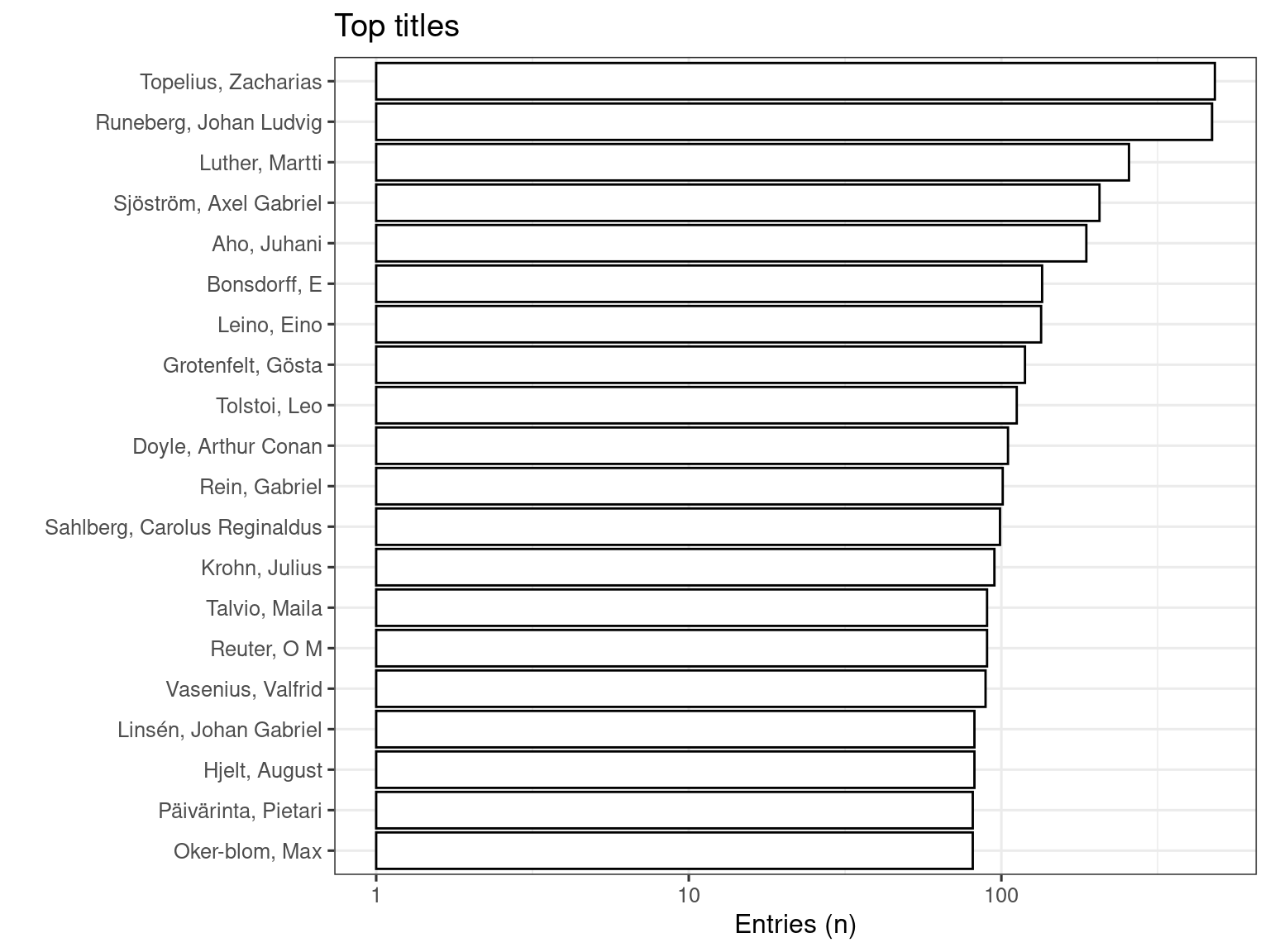
Top-20 titles and their title counts for period 1809-1917.
The accompanying plot visually underscores the prominence of these authors, emphasizing the metric of the number of unique titles published by each author.
Frequency of unique titles 1809-1917.
The plot adds a historical dimension to the analysis. By visualizing how the number of unique titles evolves over this time span, it provides insights into the literary landscape and publishing trends during the 19th and early 20th centuries.
